WSST - reassign transform for CWT
- class audioflux.WSST(num=84, radix2_exp=12, samplate=32000, low_fre=None, high_fre=None, bin_per_octave=12, wavelet_type=WaveletContinueType.MORLET, scale_type=SpectralFilterBankScaleType.OCTAVE, gamma=None, beta=None, thresh=0.001, is_padding=True)
Wavelet synchrosqueezed transform (WSST)
- Parameters
- num: int
Number of frequency bins to generate
- radix2_exp: int
fft_length=2**radix2_exp- samplate: int
Sampling rate of the incoming audio
- low_fre: float
Lowest frequency
Linear/Linsapce/Mel/Bark/Erb, low_fre>=0. default: 0.0
Octave/Log, low_fre>=32.703. default: 32.703(C1)
- high_fre: float
Highest frequency.
Default is 16000(samplate/2) Octave is not provided, it is based on musical pitch
- bin_per_octave: int
Number of bins per octave.
- scale_type: SpectralFilterBankScaleType
Spectral filter bank type. It determines the type of spectrogram.
- wavelet_type: WaveletContinueType
Wavelet continue type
Note
Default gamma/beta values for different wavelet_types:
morse: gamma=3 beta=20
morlet: gamma=6 beta=2
bump: gamma=5 beta=0.6
paul: gamma 4
dog: gamma 2 beta 2; must even
mexican: beta 2
hermit: gamma 5 beta 2
ricker: gamma 4
- gamma: float or None
gamma value
- beta: float or None
beta value
- thresh: float
thresh
- is_padding: bool
Whether to use padding.
Examples
Read 220Hz audio data
>>> import audioflux as af >>> audio_path = af.utils.sample_path('220') >>> audio_arr, sr = af.read(audio_path) >>> # WSST can only input fft_length data >>> # For radix2_exp=12, then fft_length=4096 >>> audio_arr = audio_arr[..., :4096]
Create WSST object of mel
>>> from audioflux.type import SpectralFilterBankScaleType, WaveletContinueType >>> from audioflux.utils import note_to_hz >>> obj = af.WSST(num=128, radix2_exp=12, samplate=sr, >>> bin_per_octave=12, wavelet_type=WaveletContinueType.MORSE, >>> scale_type=SpectralFilterBankScaleType.MEL, is_padding=False)
Extract spectrogram
>>> import numpy as np >>> wsst_spec_arr, cwt_spec_arr = obj.wsst(audio_arr) >>> wsst_spec_arr = np.abs(wsst_spec_arr) >>> cwt_spec_arr = np.abs(cwt_spec_arr)
Show spectrogram plot
>>> import matplotlib.pyplot as plt >>> from audioflux.display import fill_spec >>> # Show CWT >>> fig, ax = plt.subplots() >>> img = fill_spec(cwt_spec_arr, axes=ax, >>> x_coords=obj.x_coords(), >>> y_coords=obj.y_coords(), >>> x_axis='time', y_axis='log', >>> title='CWT-Mel') >>> fig.colorbar(img, ax=ax) >>> >>> # Show WSST >>> fig, ax = plt.subplots() >>> img = fill_spec(wsst_spec_arr, axes=ax, >>> x_coords=obj.x_coords(), >>> y_coords=obj.y_coords(), >>> x_axis='time', y_axis='log', >>> title='WSST-Mel') >>> fig.colorbar(img, ax=ax)
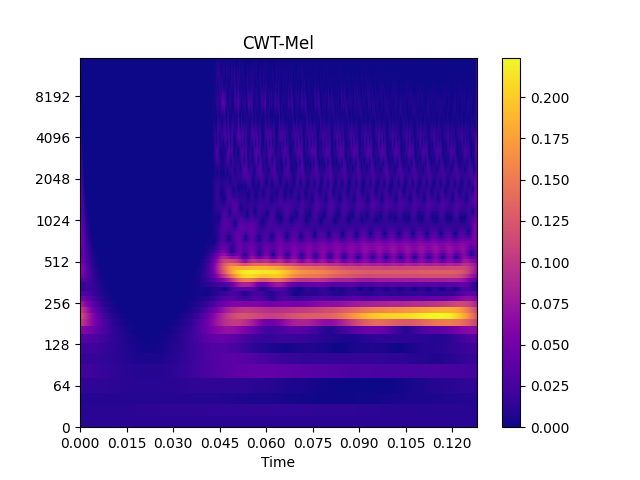
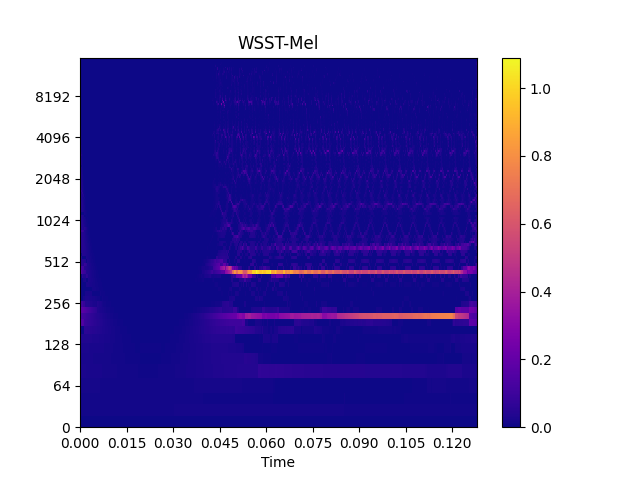
Methods
Get bin band array
Get an array of frequency bands of different scales.
set_order(order)Set order
wsst(data_arr)Get spectrogram data
x_coords()Get the X-axis coordinate
y_coords()Get the Y-axis coordinate
- get_fre_band_arr()
Get an array of frequency bands of different scales. Based on the scale_type determination of the initialization.
- Returns
- out: np.ndarray [shape=(num,)]
- get_bin_band_arr()
Get bin band array
- Returns
- out: np.ndarray [shape=(num,)]
- set_order(order)
Set order
- Parameters
- order: int, >= 1
- Returns
- wsst(data_arr)
Get spectrogram data
- Parameters
- data_arr: np.ndarray [shape=(…, 2**radix2_exp)]
Input audio data
- Returns
- m_arr1: np.ndarray [shape=(…, fre, time), dtype=np.complex]
The matrix of WSST
- m_arr2: np.ndarray [shape=(…, fre, time), dtype=np.complex]
The matrix of origin(CWT)
- y_coords()
Get the Y-axis coordinate
- Returns
- out: np.ndarray
- x_coords()
Get the X-axis coordinate
- Returns
- out: np.ndarray