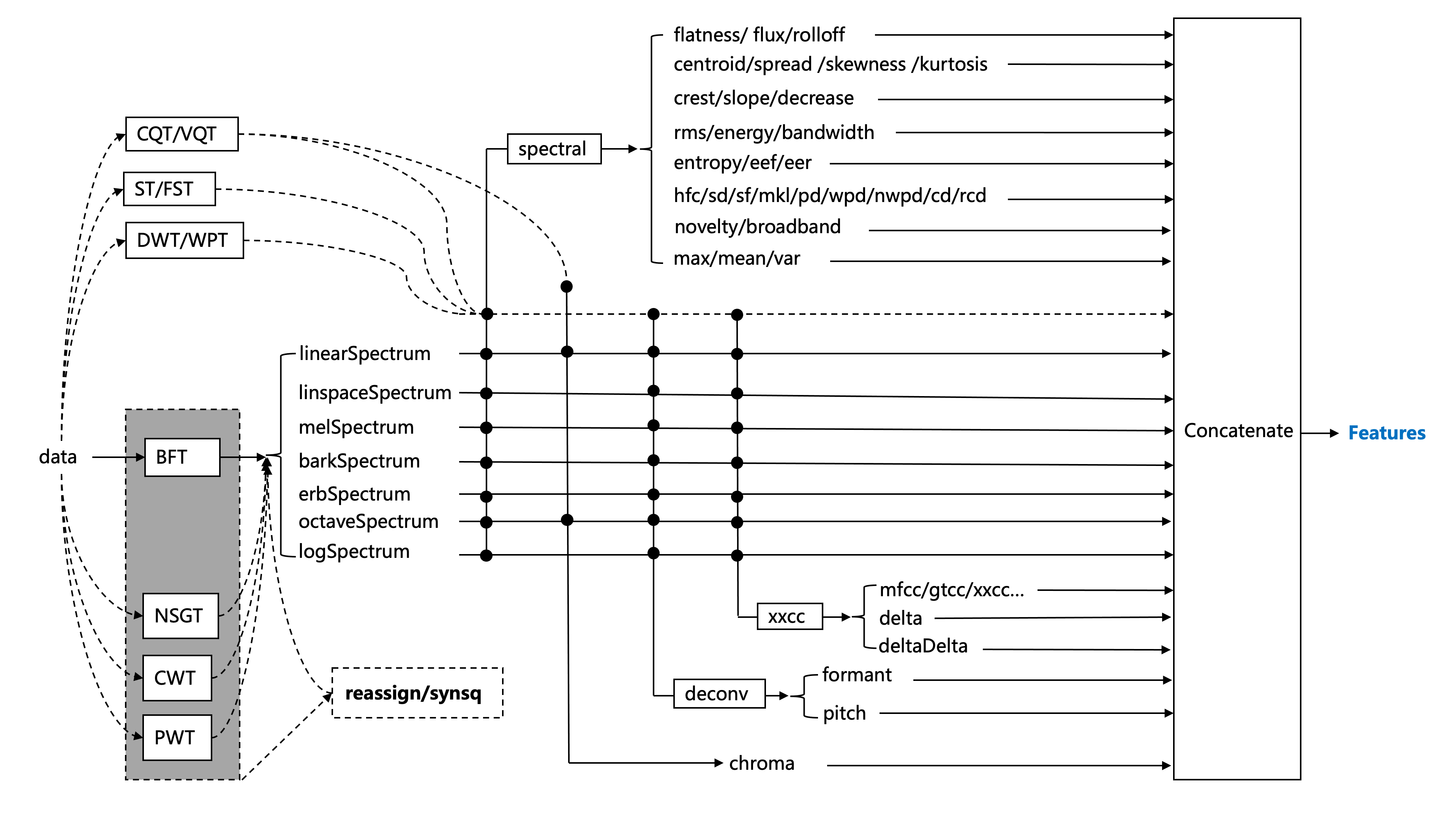
Overview
Description
In audio domain, feature extraction is particularly important for Audio Classification, Speech enhancement, Audio/Music Separation,music-information-retrieval(MIR), ASR and other audio task.
In the above tasks, mel spectrogram and mfcc features are commonly used in traditional machine-learning based on statistics and deep-learning based on neural network.
audioFlux provides systematic, comprehensive and multi-dimensional feature extraction and
combination, and combines various deep learning network models to conduct research and development
learning in different fields.
Functionality
audioFlux is based on the design of data flow. It decouples each algorithm module structurally,
and it is convenient, fast and efficient to extract features from large batches.The following are the
main feature architecture diagrams, specific and detailed description view the documentation.